Does String-Based Neural MT Learn Source Syntax?
Author Affliation: Information Sciences Institute & Computer Science Department, University of Southern California
Paper Abstract:
We investigate whether a neural, encoder decoder translation system learns syntactic information on the source side as a by-product of training. We propose two methods to detect whether the encoder has learned local and global source syntax. A fine-grained analysis of the syntactic structure learned by the encoder reveals which kinds of syntax are learned and which are missing.
Goals
- To investigate if neural machine translation systems learn any syntactic features about the source during training (as a by-product)?
- To see what kind of syntactic information is being learnt, if any?
- Evaluate both global and local syntactic information that is being learnt
Why is this important ?
Non-neural systems rely on a lot of information for machine translation. Apart from other information(wordvecs, wordtranslations), syntactic information may be provided by:
- Adding source syntax [Tree-to-String]
- Adding target syntax [String-to-Tree]
- Adding both syntax [String-to-Tree]
Neural models (Here: Vanilla seq2seq model) don’t require such artillery to provide competitive translation systems.
This paper is a step towards understanding what is going inside such models and how are they performing well.
A nice example
Setup
- English-French NMT system trained on 110M tokens of bilingual data (English-side).
- English-English autoencoder system.
Steps
- Take 10K separate english and label their voice (active/passive)
- Use trained NMT/autoencoder to convert into 10k corresponding 1000-dimension encoding vectors (Seq to vec to seq)
- Use 9k sentences for training a logistic regression model to predict voice
- 1k for testing
Observation
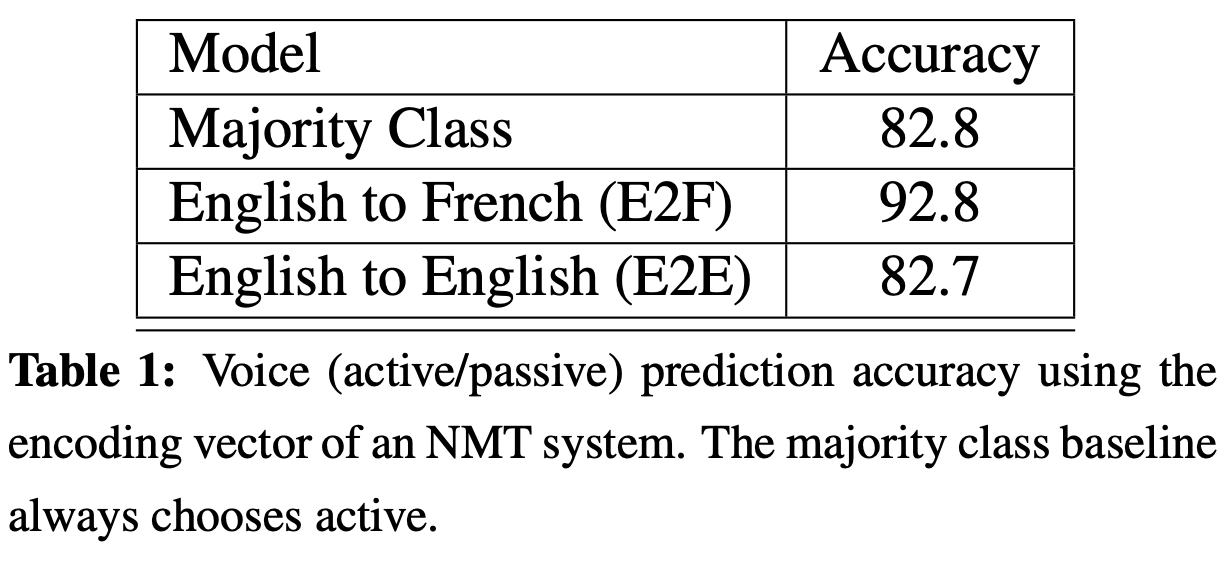
Accuracy a: 92.7% b: 82.6%
Verdict: Syntactic information is learnt in NMT but not so in autoencoder.
Experiments
Model: Two layered LSTM based models
- E2E (English-to-english) [LOWER BOUND MODEL]
- PE2PE (PermutedEnglish-to-Permutedenglish) [LOWER BOUND MODEL]
- E2P (English-to-ParseTree) [UPPER BOUND MODEL]
- E2F (English-to-French)
- E2G (English-to-German)
An improvement of syntactic tree generation over the lower bound models indicates that the encoder learns syntactic information, whereas a decline from the upper bound model shows that the encoder loses certain syntactic information
Global Syntax
- Voice : active or passive
- Tense : past or non-past
- TSS : Top-level syntactic sequence of the constituent tree. (Only top 19. Rest are treated as others)
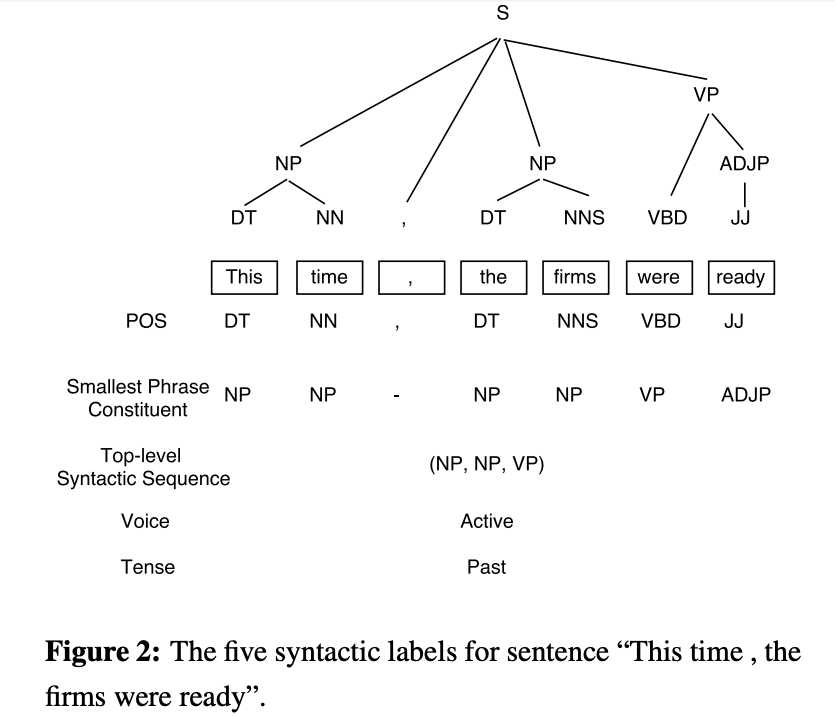
Local Syntax
- POS : Tags for each word
- SPC: Smallest phrase constituent above each word (HIGHER LEVEL POS TAGS)
Results
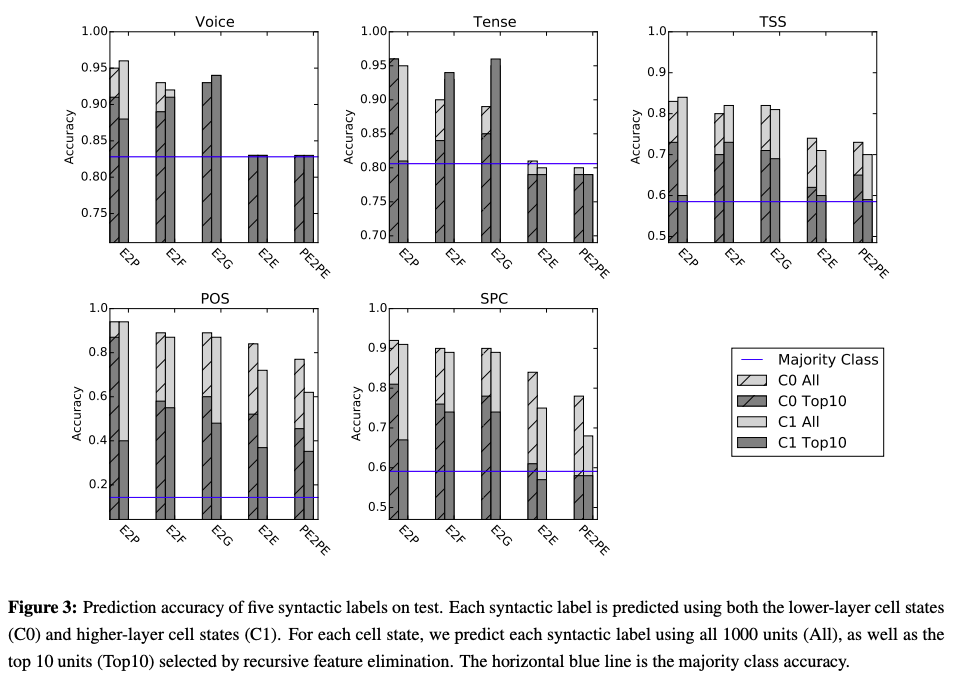
- NMT encoder learns significant sentence-level syntactic-information. It can distinguish voice and tense of the source sentence and it knows the sentence's structure to some extent.
- Different syntactic information is captured in different layers as can be see from Figure 3. Local features are preserved in lower layers whereas global abstract information gets stored in upper layers. Model is two layered.
- Units = Hidden states. While predicting POS, the gap of neural parser (E2P) on the lower layer (C0) is much smaller. Small subset of units explicitly takes charge of POS tags in the neural parse, whereas for NMT the POS information is more distributed and implicit.
- No large difference between E2F and E2G
Extracting Syntactic Tree from Encoder
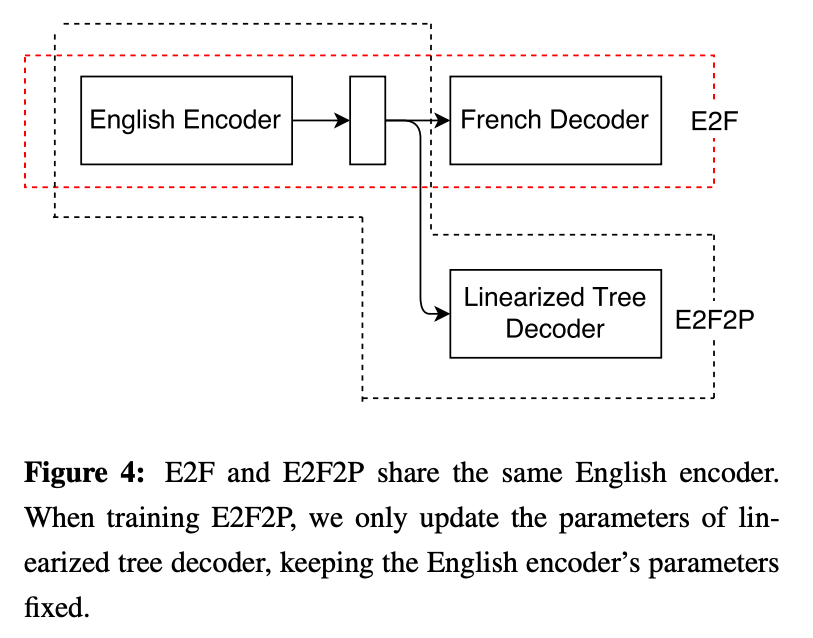
Evaluation Tools
- EVALB tool to calculate labeled bracketing F1-score
- zxx package for Tree edit distance
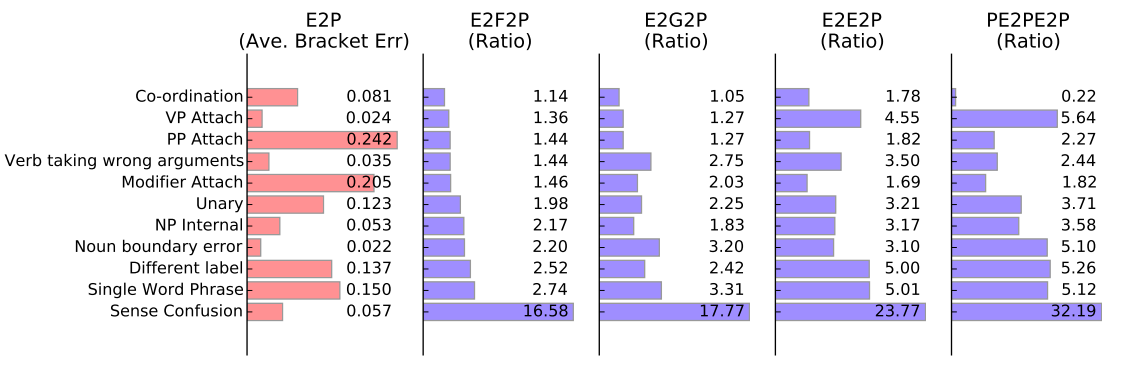
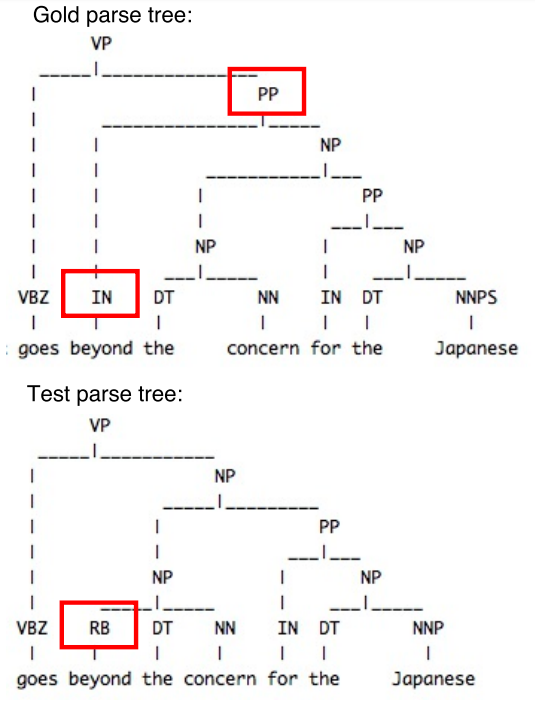
- Berkeley Parser Analyser to analyse parsing error types.

Leave a comment